ADsP 3과목. 데이터 분석
| 작성일 | 2024년 02월 03일 |
|---|---|
| 수정일 | 2026년 01월 10일 |
| 카테고리 | 취미 |
| 태그 | |
| 원본 | https://croot.notion.site/7d949b41d55740848dfd14676c7c842a |
3. 데이터 분석
3.1. 탐색적 데이터분석 (EDA)
탐색적 데이터분석 정의
데이터의 분포, 통계 등을 시각화하여 데이터를 이해하고 의미있는 관계를 찾아내는 분석 기법
결측값
- 정의 : 존재하지 않는 데이터
- 표현 방식 : NA , null , -1
- 대치 기법
- 단순 대치법 : 값 삭제
- 평균 대치법 : 평균이나 중앙값을 이용,
- 조건부 평균 대치법 : 회귀분석을 통해 좀 더 신뢰성이 높음
- 단순확률 대치법 : k-NN
- 다중 대치법 : 여러 번 대치 시행, (대치 → 분석 → 결합)
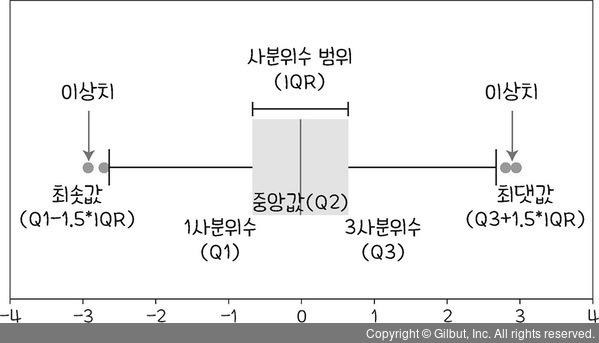
이상값
- 정의 : 다른 데이터와 비교 했을 때 극단적으로 크거나 작은 값
- 판단 기법
- ESD : 평균으로부터 표준편차 * 3
-
사분위수 : IQR 기반
 Untitled.png
Untitled.png
3.2. 통계 분석
통계 분석 용어 및 기초
- 기대값 : 확률변수 X가 취할 수 있는 값의 평균 값
-
공분산(Covariance) : 확률변수 X, Y의 상관 정도
표현식: $\text{Cov}(X, Y)$
-
상관계수(Correlation) : 공분산을 X, Y의 표준편차 모두로 나눈 값
표현식: ${r_x}_y$
- 독립사건: 서로 영향을 주지 않는 두 개의 사건
- 배반사건: 두 사건이 교집합이 없는 경우
- 확률변수: 특정확률로 발생하는 각 변수를 수치값으로 표현하는 변수
- 연속확률변수: 구간 내 모든 값을 취하는 확률변수
- 이산확률변수: 셀 수 있는 확률변수
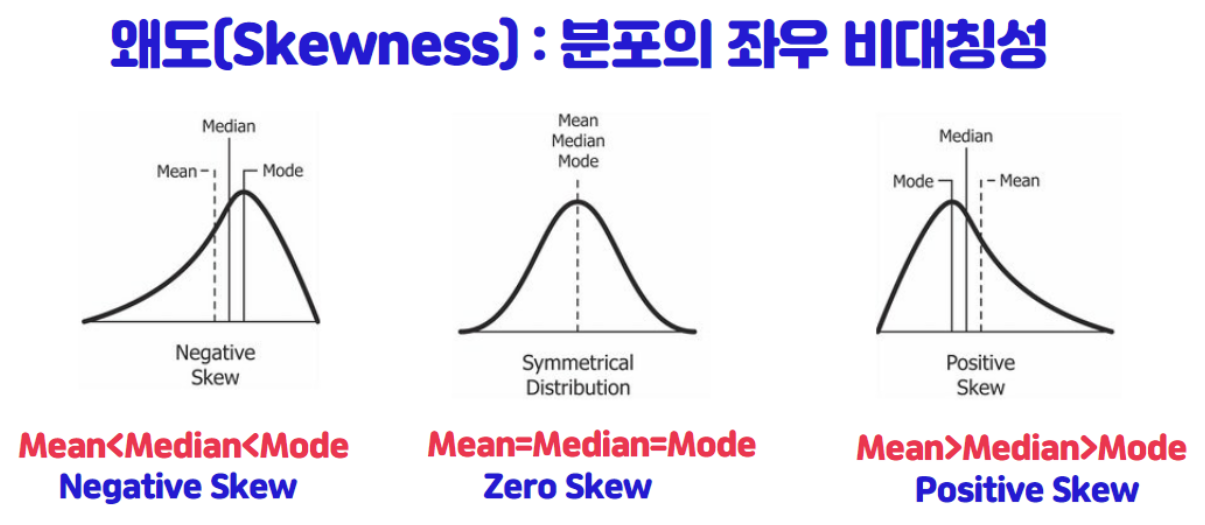
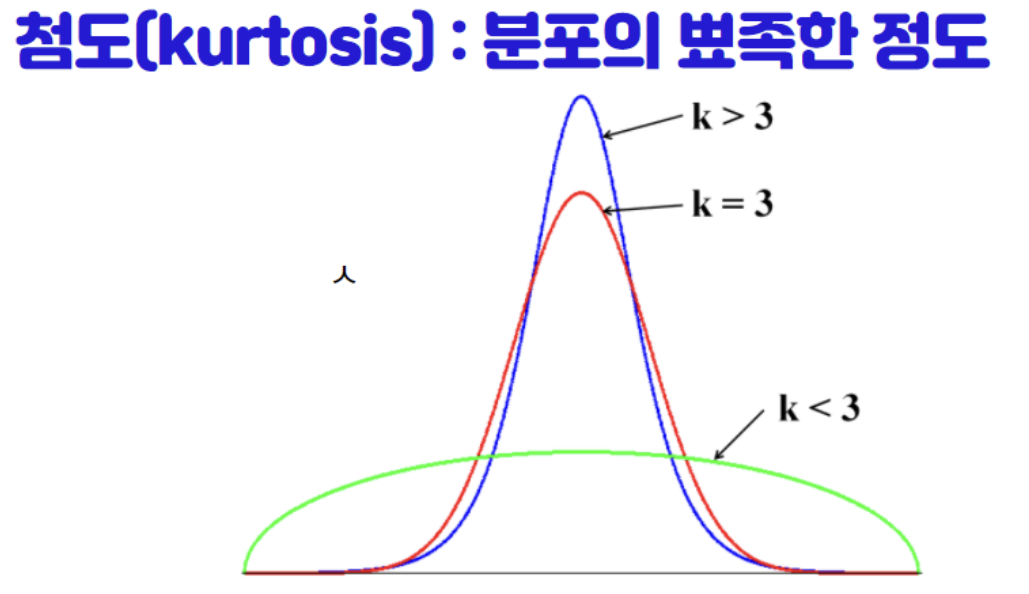
왜도(Skewness)와 첨도(Kurtosis)
 Untitled.png
Untitled.png
 Untitled.png
Untitled.png
왜도 : 실수 값 확률변수의 확률 분포 비대칭성을 나타내는 지표
- **Negative** : 음수 값이며 왼쪽 긴꼬리를 가짐
- mean(평균) < median(중위값) < mode(최빈값)
- **Zero** : 0으로 표현하며 좌우 대칭적
- mean(평균) = median(중위값) = mode(최빈값)
- **Positive** : 양수 값이며 오른쪽 긴꼬리를 가짐
- mean(평균) > median(중위값) > mode(최빈값)
첨도 : 분포의 중심에서 뾰족한 정도를 나타내는 값
- 0(k=3)보다 크면 뾰족, 작으면 완만
통계 분석 표본추출
- 유형
- 복원 추출 : 모집단 복원
- 비복원 추출 : 추출 데이터 제외
- 기법 (단계클층)
- 단순랜덤
- 계통 추출법 : K=N/n
- Cluster 추출법 : Cluster 내 이질적 Data
- 층화 추출법 : cluster 내 동질적 Data, 비례(분포반영), 불비례(분포미반영)
측정과 척도 (명순구비)
| 구분 | 유형 | 특징 | 예시 |
|---|---|---|---|
| 질적 척도 | 명목 척도 | 어느 집단에 속하는지 나타내는 자료 | 성별, 지역 등 |
| 순서(서열) 척도 | 명목척도 이면서 서열 관계를 갖는 자료 | 선호도, 신용도, 학년 등 | |
| 양적 척도 | 구간(등간) 척도 | 속성의 양을 측정할 수 있고 구간 사이에 의미가 있는 자료 | 온도, 지수 등 |
| 비율 척도 | 구간척도이면서 절대기준(0)이 존재하여 연산이 가능한 자료 | 신장, 무게, 점수, 가격 등 |
기술통계와 추리통계
- 기술통계 : 표본 제차의 속성이나 특징을 파악하는 데 중점을 두는 데이터 분석 통계
- 모집단의 특성을 유추하는데 사용 (최소값, 최댓값, 중위수 등)
- 추리통계 : 수집한 데이터를 바탕으로 추론 및 예측하는 통계 기법
- 모수를 확률적으로 추정 (미래 사건 예측)
- 편차(difference) : 평균과의 차이
- $d(X)$
- 분산(variance) : 편차 제곱하여 모두 합한 뒤 데이터 개수로 나눔.
- $Var(X)=E(X^2)-{E(X)}^2$
- 표준편차(Standard Deviation) : 단위를 일치 시키기 위해 분산에 루트를 씌워서 구함.
- $sd(X) = √\overline{Var(X)}$
- 기댓값 : 확률변수 X가 취할 수 있는 값의 평균 값
- 이산확률변수의 기댓값 : $E(X) = \Sigma xf(x)$
- 연속확률변수의 기댓값 : $E(X) = \Sigma xf(x)dx$
- 공분산(Covariance) : 확률변수 X, Y의 상관 정도
- $Cov(X, Y)$
- 상관계수(Correlation) : 공분산을 X, Y의 표준편차 모두로 나눈 값
- ${r_x}_y$
확률
- 이산확률분포
-
베르누이 분포
$P(X = k) = p^k(1 - p)^{1-k}$
-
이항 분포 : n번의 베르누이 시행 결과의 확률분포 (ex: 동전던지기)
$P(X = k) = \binom{n}{k} p^k (1 - p)^{n - k}$
-
기하 분포 : 처음 성공하기까지 의 확률분포
$P(X = k) = (1 - p)^{k-1} p$
-
다항 분포 : 3가지 이상의 결과에 대한 확률분포 (ex: 주사위)
$P(X_1 = x_1, X_2 = x_2, \ldots, X_k = x_k) = \frac{n!}{x_1! \cdot x_2! \cdots x_k!} p_1^{x_1} p_2^{x_2} \cdots p_k^{x_k}$
-
포아송 분포 : 특정 시간/공간 안에 성공하는 횟수의 확률분포
$P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}$
-
- 연속확률분포
- 균일 분포 : 모든 독립변수가 동일한 확률을 가지는 분포
- 정규 분포 : 평균과 표준편차를 가지는 종 모양 그래프
- t-분포 : 평균이 0, 모평균 검정 및 집단 간 평균 비교
- 모평균 검정, 집단 평균 비교 계산에 이용.
- 카이제곱 분포 : 정규분포를 따르는 확률 변수들의 제곱을 합하여 얻는 분포
- 분산 추정, 독립성 검정, 적합도 검정 등에 사용
- F 분포 : 두 모집단의 분산이 같은지를 비교하기 위한 분포
- 분산분석(ANOVA) 에서 사용
추정
- 점 추정: 모평균을 하나의 특정 값이라고 예측하는 것
- 구간 추정: 모평균을 특정 구간 안에 존재한다고 예측하는 것
가설검정
- 귀무가설($H_0$) : 기각하고자 하는 가설
- 대립가설($H_1$) : 증명하고자 하는 가설
- 제1종 오류 : 귀무가설이 맞지만 기각하는 오류
- 제2종 오류 : 귀무가설이 거짓이지만 채택하는 오류
- 검정통계량 : 귀무가설을 판단할 수 있는 값
- 기각역 : 귀무가설을 기각하게 될 검정통계량의 영역
- 유의수준 : 제1종오류의 최대허용한계 (보통 0.05)
- 유의확률 (p-value) : 귀무가설 지지 확률
- 모수검정 : 표본이 정규성을 가진다는 모수적 특성을 이용하는 통계 방식
- 비모수 검정 : 모수적 특성을 이용하지 않은 통계 방식
| 구분 | 모수 검정 | 비모수 검정 |
|---|---|---|
| 적용 유형 | 등간척도, 비율척도 | 명목척도, 서열척도 |
| 검정 대상 | 평균 | 중앙값 |
| 상관계수 | 피어슨 상관계수 | 스피어만 순위상관계수 |
| 사용예시 | t-test, ANOVA | 부호검정, 프리드만 검정, 연속성 검정, 순위 합 검정, 크러스컬-월리스 검정 등 |
3.3. 비교 분석 기법
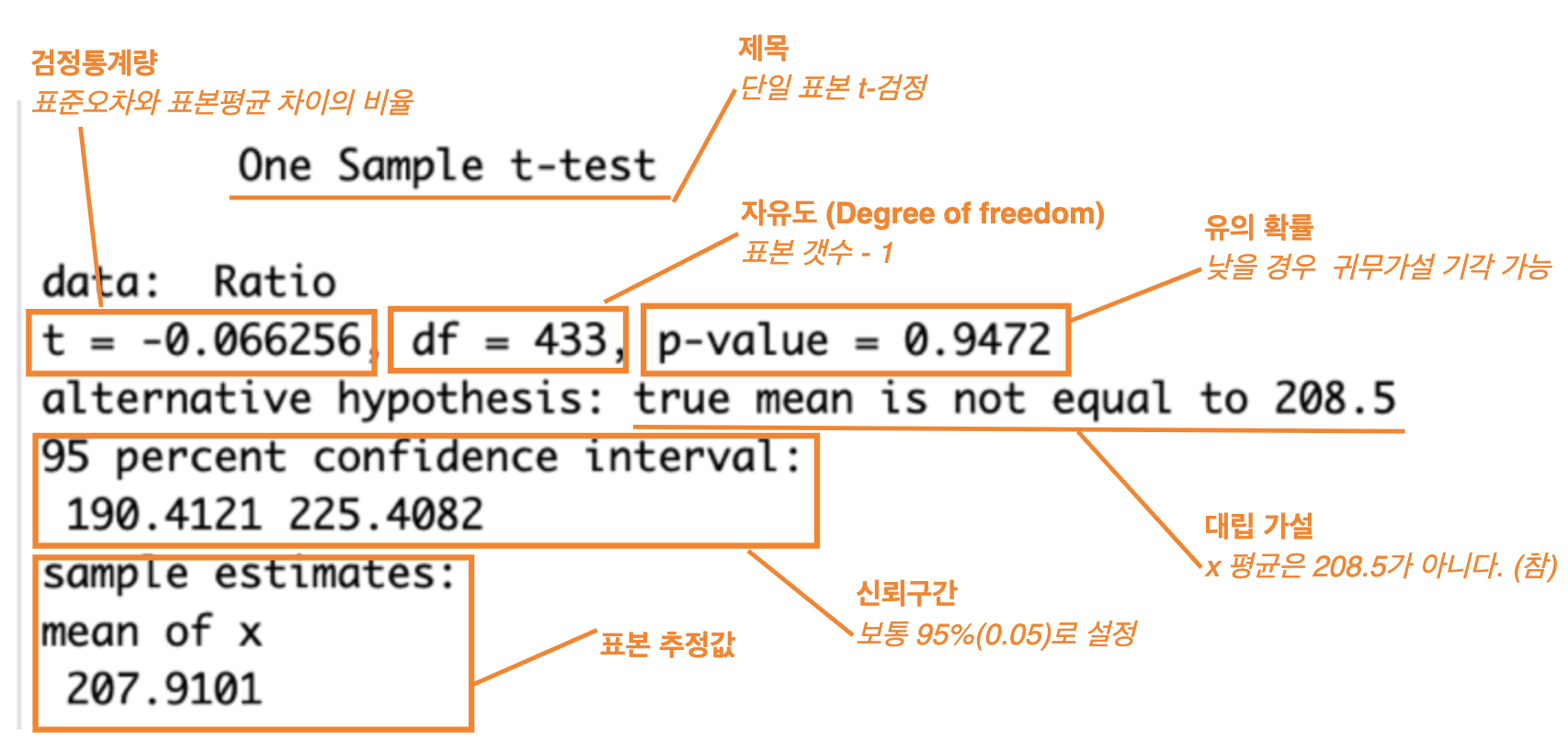
t-test
- 정의 : 하나의 모집단의 **평균값**을 특정값과 비교하는 분석 기법.
- 유형
- 단일표본(one sample) : 하나의 모집단 평균값과 특정 값 비교
- 단측(one way) : 모수값이 한쪽으로만 방향성을 갖는 경우 (~ 보다 크다, 작다)
- 양측(two way) : 방향성이 없는 경우 (~이다, 아니다)
- 독립표본(independent sample) : 서로 독립적인 두 집단의 모수값 비교
- 단측(one way) : 두 집단 간 대소가 있는 경우 (~이 ~보다 크다, 작다)
- 양측(two way) : 두 집단 간 대소가 없는 경우 (두 집단이 같다, 다르다)
- 대응표본(paired) : 동일 대상의 두가지 관측치를 비교
- 단일표본(one sample) : 하나의 모집단 평균값과 특정 값 비교
- 결과 해석
 Untitled.png
Untitled.png
ANOVA(분산분석)
- 정의 : 세 개 이상의 모집단 평균을 비교
- 가정사항: 정규성, 등분산성, 독립성
- 유형
- one-way : 독립변수와 종속변수 모두 한 개인 경우
- two-way : 독립변수가 2개 이상인 경우
- 교호작용 여부에 따라 반복실험
- 결과 해석
 Untitled.png
Untitled.png
| Summary | Df (자유도) | 제곱 합 | 제곱 평균 | F-value | p-value |
|---|---|---|---|---|---|
| 처리 (집단 명) | 집단 수 - 1 | SSR | MSR | MSR / MSE | 유의 확률 |
| 잔차 | 전체 데이터 - 집단 수 | SSE | MSE | - | - |
| 합계 | 전체 데이터 - 1 | SST | - | - | - |
SSR : 평균과 회귀값의 차이들의 제곱의 합
SSE : 잔차들의 제곱의 합
SST : 편차들의 제곱의 합 (SSR + SSE)
MSR : 평균 제곱 회귀 (Mean Squares Regression)
MSE : 평균 제곱 오차 (Mean Squares Error)
교차분석
- 정의 : **카이제곱 검정통계량**을 이용하여 **범주형 자료(명목,서열)** 간 관계 분석
-
교차분석표
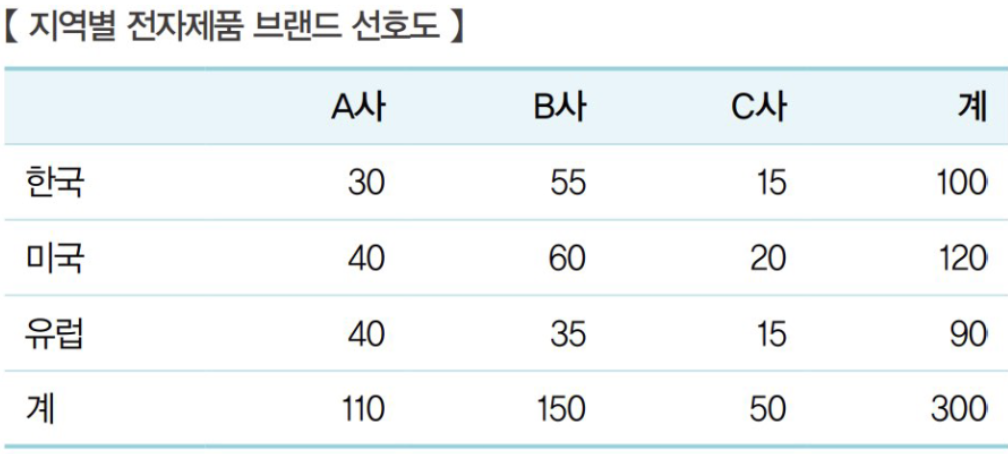 Untitled.png
Untitled.png - 활용
- 적합도 검정: 관측값과 예상**값 일치 여부**
- 독립성 검정: 두 변수 간 **관계가 독립적**인지 판단
- 동질성 검정: **정해진 범주 내**에서 관측값이 비슷한지 여부
상관분석
- 정의 : 변수 간 선형적 관계 존재 분석 기법, **상관계수** 활용
- 종류
- 피어슨
- 선형적 상관관계
- 모수적 방법으로 등간척도, 비율척도 시 사용
- 스피어만 (스비서)
- 비선형적 상관관계
- 비모수적 방법으로 서열척도 시 사용
구분 피어슨 스피어만 자료 형태 모수 비모수 자료 척도 등간척도, 비율척도 서열척도 결과값 피어슨 상관계수 스피어만 상관계수 - 피어슨
- 결과 해석
 Untitled.png
Untitled.png
3.4. 회귀 분석 기법
회귀 분석 정의
하나 이상의 독립변수가 종속변수에게 미치는 영향을 추정하는 기법.
회귀 분석 종류
- 단순 회귀 : 1개의 독립변수, 직선 관계
- 다중 회귀 : k개의 독립변수, 선형 관계
- 다항 회귀 : 4개의 독립변수, 2차함수 이상 관계
- 비선형 회귀 : 지수함수, 로그함수, 삼각함수 등
회귀 분석 전제조건 (정등독선)
- 정규성 : 오차항이 정규분포 형태를 띄어야한다.
- 검증 : 히스토그램, QQ plot, 샤피로 검정, 앤더스-달링 검정, 하르케-베라 검정
- 등분산성 : 오차들이 고르게 분포해야한다.
- 독립성 : 독립변수들 간에 상관성이 없어야 한다, 오차항은 독립변수로부터 독립성을 가져야 한다.
- 선형성 : 독립변수와 종속변수가 선형적이여야 한다.
분산분석표
| 요인 | 제곱 합 | Df (자유도) | 제곱 평균 | F-value |
|---|---|---|---|---|
| 회귀 | SSR | k | MSR = SSR/k | MSR / MSE |
| 잔차 | SSE | n-k-1 | MSE = SSE/(n-k-1) | MSR / MSE |
| 총 | SST = SSR + SSE | n-1 | - | MSR / MSE |
단순선형회귀에서는 k = 1 이다.
 Untitled.png
Untitled.png
회귀분석 결과 해석
 Untitled.png
Untitled.png
단순선형회귀분석
- 계수 추정: 최소제곱법 (오차를 제곱해 더한 값)
- 적합성
- 통계적 유의성 검증 = F 검정 (분산 차)
- 회귀계수 유의성 검증 = t-검정
- 설명력 검증 = 분산분석 후 결정계수($R^2$)가 1에 가까울수록 좋음
다중선형회귀분석
- 다중공선성
- 정의: 독립변수 간 강한 상관관계가 나타나는 문제
- 진단
- 회귀식의 설명력 높지만 각 독립변수 p-value 큰 경우
- 분산팽창요인(VIF)가 10 이상 인 경우
- 해결
- 문제변수 제거
- 차원축소(PCA, LDA, t-SNE, SVD)
- 주성분개수 선택 (scree plot 이용)
최적 회귀방정식
- 정의: 모델 성능향상을 위해 종속변수에 유의미한 영향을 끼치는 독립변수를 선택하는 과정
- 변수 선택법
- 유형
- 부분집합법 : 모든 가능한 모델을 고려
- 단계적 변수선택법 : 일정한 단계를 거치는 방식
- 전진선택법 : 가장 많은 영향을 줄 것 같은 변수부터 추가
- 후진제거법 : 가장 적은 영향을 주는 변수부터 제거
- 단계선택법 : 전진선택법 + 후진제거법 에 패널티 값을 부여
- 성능지표
- AIC : MSE에 변수 수만큼 페널티를 주는 지표 // 단점: 표본이 커질 때 부정확함
- BIC : AIC 단점을 보완한 지표, 표본이 커지면 더 큰 페널티 부여
- 멜로우 Cp : Cp값은 최소자승법으로 사용
- 유형
고급회귀분석
- 정규화 선형회귀
- 정의 : 과적합 시 계수의 크기가 과도하게 증가하는 걸 방지하기 위해 **계수 크기 제한**하는 방법
- 유형 :
- Lasso (L1 penalty) : 가중치 **절댓값의 합**을 최소화
- Lidge (L2 penalty) : 가중치들의 **제곱합**을 최소화
- Elastic Net : 라쏘 + 릿지
- 일반화 선형회귀
- 구성요소
- 확률요소 : 종속변수의 확률분포를 규정하는 성분
- 선형예측자 : 종속변수의 기댓값을 정의하는 독립변수들 간의 선형 결합
- 연결함수 : 확률 요소와 선형예측자를 연결하는 함수
- 종류
- 로지스틱 회귀
- 포아송 회귀
- 구성요소
- 더빗 왓슨 검정 : 회귀분석에 있어 자기상관성이 존재하는지 검정하는 방법.
- 통계량 값이 2에 가까울수록 좋음.
- 0에 가까울수록 양의 상관관계
- 4에 가까울수록 음의 상관관계
회귀분석 평가지표
-
MAE(Mean Absolute Error) : 평균 절대 오차
$\frac{1}{n} \sum_{i=1}^{n} y_i - \hat{y}_i $ -
MSE(Mean Squared Error) : 평균 제곱 오차
$\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$
-
RMSE(Root Mean Squared Error) : 평균 제곱근 오차
$\sqrt{MSE}$
-
MSLE(Mean Sequared Log Error) : MSE에서 타깃값에 로그를 취한 값
$\frac{1}{n} \sum_{i=1}^{n} (\log(1 + y_i) - \log(1 + \hat{y}_i))^2$
-
RMSLE(Root Mean Sequared Log Error) : MSLE에 제곱근을 취한 값
$\sqrt{MSLE}$
-
MAPE(Mean Absolute Percentage Error) : 평균 절대 비율 오차
$\frac{1}{n} \sum_{i=1}^{n} \left \frac{y_i - \hat{y}_i}{y_i}\right \times 100\%$ -
R2 (R square) : 실제 값의 분산 대비 예측값의 분산 비율
$1-\frac{SSE}{SST}$
3.5. 다변량 분석 기법
다차원 척도법(MDS ;Multidimensional Scaling)
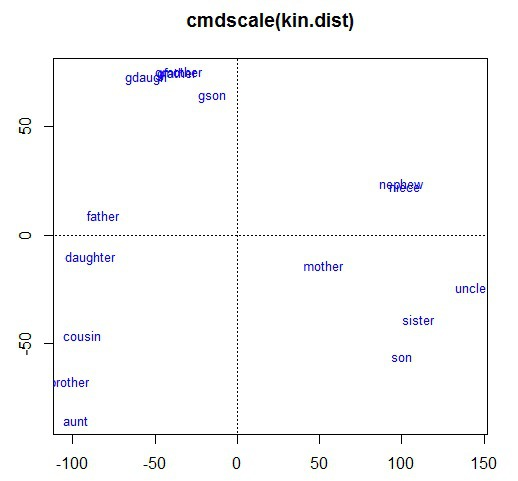 Untitled.png
Untitled.png
- 정의 : **데이터 축소**를 목적으로 **유클리디안 거리행렬**을 사용하여 객체 간의 **근접성을 시각화**하는 통계기법
- 측도: stress 척도를 사용하며 낮을수록 적합도가 높다고 평가함.
- $\text{stress} = \sqrt{\frac{\sum(\text{실제거리}-\text{추정거리})^2}{\sum\text{실제거리}^2}} $
- 0 ~ 0.05 = 적합도 좋음 , 0.15 ~ 1 = 적합도 나쁨
-
종류
구분 계량적 MDS 비계량적 MDS 대상 구간척도, 비율척도 서열척도 거리 유클라디안 거리 행렬 서열 → 거리 속성 변환 R 함수 Cmdscale isoMDS
주성분분석
- 정의 : 서로 상관성이 높은 변수들의 선형 결합으로 새로운 변수(주성분)을 만들어 요약 및 축소하는 분석 방법.
- 목적 :
- 축소하여 모델의 **설명력 높임**
- 분산이 큰 축을 이용하기 때문에 **다중공선성 문제 해결**
- 모형의 성능 향상
- 특징
- 데이터 손실 발생
- 계산이 간단, 정렬되지 않은 데이터 처리 가능
3.6. 시계열 분석
시계열 분석 정의
일정 시간 간격으로 기록된 자료들의 특성을 파악하여 미래를 예측하는 분석방법
시계열 자료의 정상성 조건
- 일정한 평균 : 모든 시점에 대해 평균이 일정해야 함.
- 차분을 이용하여 정상화
- 차분: 현 시점 자료 값에서 이전 시점 자료 값을 빼는 것.
- 일정한 분산 : 모든 시점에 대해 분산이 일정해야 함.
- 변환(지수, 로그)을 통해 정상화
- 시차에만 의존하는 공분산 : 공분산은 특정 시점에 의존하지 않음
시계열 분석의 자기상관계수
- 자기상관계수(ACF ;Autocorrelation Function)
- 두 시계열 확률변수 간 상관관계를 보여준다.
- 시계열 자료의 무작위성 확인
- 부분자기상관계수(PACF ;Partial ACF)
- 두 시계열 확률변수 간에 다른 시점의 확률변수 영향력을 통제한 상관관계를 보여준다.
정상 시계열
- 평균이 일정 모든시점에 일정함
- 정상 시계열은 항상 평균값으로 회귀하려함, 평균값 주면 변동은 일정폭을 갖음
- 백색잡음(White Noise)이 대표적인 예시
- 정규분포로부터 추출된 데이터, 오차항에 해당
- 가우시안 백색잡음 : 평균이 0이면서 분산이 일정한 정규분포
분해(비정상) 시계열
- 정의 : 분석 목적에 따라 특정 요인만 분리해 분석하거나 제거하는 작업.
- 구성요소
- 추세 : 장기간 일정 방향 상승 또는 하락하는 경향을 보이는 요인
- 주기 : 반복 운동하는 형태
- 계절성 : 일정한 주기를 가지는 상하 반복의 규칙적인 변동
- 랜덤(불규칙) : 규칙성 없이 우연히 발생하는 예측 불가능한 변동
- 확률보행(random work)이 대표적인 예시
시계열 분석 기법
- 이동평균법 : 일정 기간별로 자료를 묶어 평균을 구하는 방법
- 지수평활법 : 이동평균법에 최근 데이터일수록 큰 가중치를 부여하는 방법
시계열 모형
- 자기회귀(AR) : 이전시점 자료 선형 결합
- 이동평균(MA) : 이전시점 백색잡음 선형 결합
- 자기회귀누적이동 평균(ARIMA) : 비정상 시계열 자료 모형.
3.7. 데이터 마이닝
데이터 마이닝 정의
방대한 양의 데이터 속에 숨겨진 패턴, 규칙 등을 찾아 예측, 의사결정 지원에 활용하는 기술
데이터 마이닝 분류
방식 별 분류
- 지도학습
- 회귀(연속형) : Linear regression, SVR, 신경망, Ridge, Lasso
- 분류(범주형) : Logistic Regression, Decision Tree, K-NN, Ensemble, SVM, 나이브 베이즈
- 비지도학습
- 군집 : k-means, SOM, DBSCAN
- 연관 : Apriori
- 차원축소 : PCA(주성분분석), LDA(선형판별분석), SVD(특잇값 분해), MDS(다차원 척도법)
목적 별 분류
- 분류 : Logistic Regression, Decision Tree, Ensemble, 신경망, k-NN
- 군집 : 병합, 분할, K-means
- 연관 : Apriori
데이터 마이닝 프로세스
- 목적 정의
- 데이터 준비
- 데이터셋 분할 유형
- 훈련(5):검증(3):평가(2)
- 훈련(6):검증(2):평가(2)
- 데이터셋 분할 유형
- 데이터 가공
- 데이터 마이닝 기법적용
- 검증
- 검증 기법
- Holdout : 전체데이터 → 학습(80), 검증(20)
- K-fold Coss : k개 집단, 과적합(과소적합)예방
- LOOCV : 전체 N개 데이터셋을 K개 집단으로 분할, 매우 느림
- Bootstrap : 복원추출, 신뢰성 평가, 과적합 예방
- 계층별 k-fold cross : 불균형 데이터 분류 시 사용, k-fold 와 동일
- 검증 기법
데이터마이닝 vs 통계분석
| 구분 | 데이터 마이닝 | 통계분석 |
|---|---|---|
| 표본 | 불필요 | 필요 |
| 가설 검정 | 선택적 | 필수적 |
| 분석유형 | 상향식 | 하향식 |
3.8. 분류분석
로지스틱 회귀 분석
- 독립변수가 연속형이면서 종속변수(y)가 범주형 변수일 때 사용
- 변수가 3개 이상이면 다중 로지스틱 회귀분석
- 알고리즘 유형 :
-
Odds : 성공할 확률이 실패할 확률의 몇 배인지 나타내는 값
$\frac{P}{1-P}$ (P = 성공확률)
-
Logit 변환 : Odds에 로그를 취한 값
$log(Odds) = \text{log}\frac{P}{1-P}$ (P = 성공확률)
-
Sigmoid : 대표 활성화 함수, 로짓 함수와 역함수 관계
$p = \frac{1}{1+e^{-(\beta_0+\beta_1X)}}$ (P = 성공확률)
-
의사결정나무
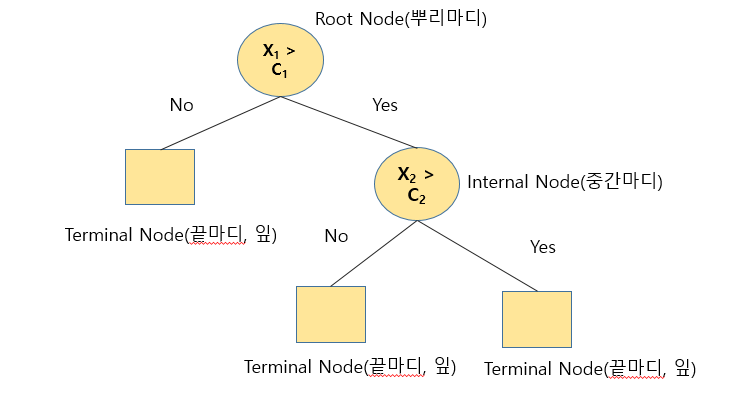 Untitled.png
Untitled.png
정의 : 특정 분리 규칙을 찾아내어 몇 개의 소집단으로 분류하는 분석 방법
특징 : 집단 내 동질성↑, 집단 간 이질성↑
- 장점 : 직관적, 정규화 불필요, 이상값
- 단점 : 과적합 발생, 경계선 오차
구성요소
- Root Node : 가장 최상위 마디
- Child Node : 하나의 마디로부터 나온 2개 이상의 하위 마디
- Parent Node : 모든 자식마디의 바로 상위 마디
- Terminal Node : 자식마디가 없는 최하위 마디
- Intermediate Node : 부모마디와 자식마디를 모두 보유한 마디
- Branch : 부모마디와 자식마디를 연결하는 선
- Depth : 뿌리마디를 제외한 중간마디 수
활용 : 세분화, 분류, 예측, 차원축소, 교호작용
분석과정
1. 성장 : 분리기준(불순도) 와 정지규칙 이용
- 분리기준 :
- 이산형 : 카이제곱(CHAID), 지니지수(CART),엔트로피 지수 (C4.5)
- 연속형: ANOVA-F 통계량(CHAID 이용), 분산감소량(CART 이용)
2. 가지치기 : 과적합 및 과소적합 방지 목적
3. 타당성 평가 : 검증 데이터, 이익 도표, 평가 지표 활용하여 평가
4. 해석 및 예측 : 예측 적용 및 해석 단계
앙상블
정의 : 여러 개의 모형을 생성 및 조합하여 예측력이 높은 모형을 만드는 기법
종류 :
- **Bagging** : 복원추출(부트스트랩) → 분류기 → Voting
- **Boosting** : 복원추출(부트스트랩) → Weight 적용추출(부트스트랩)
- **Random Forest** : 복원추출(부트스트랩) → 비복원추출(표본) → 분류기 → Voting
인공신경망
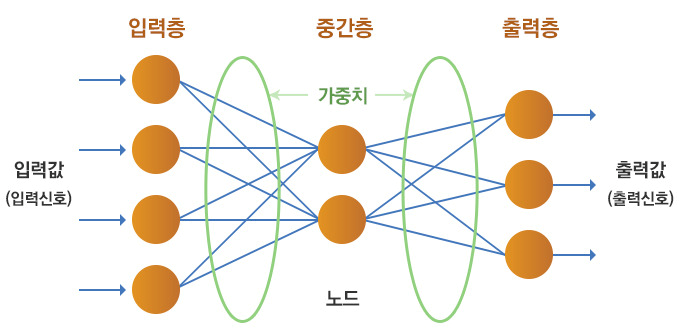 Untitled.png
Untitled.png
정의 : 인간의 뇌를 모방하여 만들어진 학습 및 추론 모형
특징
- 장점
- 잡음에 민감하지 않음
- 비선형적 문제 분석에 유용
- 단점
- 복잡한 모형은 오랜 시간 소요
- 추정 가중치의 신뢰도 낮음
- 은닉층, 은닉노드 수 결정 어려움
종류
- 단층 퍼셉트론 : 은닉층 1개 or 없음
- 다층 퍼셉트론 : 은닉층 2개 이상
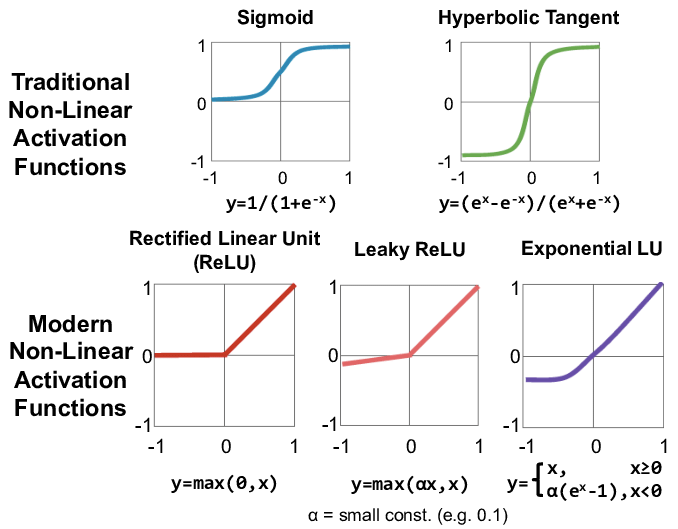 Untitled.png
Untitled.png
활성함수 유형
- **Step** : 0 or 1을 반환하는 이진형 함수
- **Sign** : -1 or 1을 반환하는 이진형 함수
- **Sigmoid** : 0~1 사이의 값을 반환
- **Tanh** : 시그모이드의 확장형으로 -1 ~ 1 사이 값을 출력
- **RELU** : 입력값과 0 중 큰 값을 반환
- **Softmax** : 표준화지수 함수, 각 범주에 속할 확률값을 반환
학습 단계
1. 순전파 알고리즘
2. 오차확인
3. 역전파 알고리즘
4. 가중치 업데이트
구조유형
- RNN : 순환 신경망, 주로 언어/음성인식에 활용
- CNN : 합성곱 신경망, 이미지에 주로 사용
- LSTM : 장단기 메모리 신경망
- GRU : LSTM 장기 메모리 소실 문제 개선
- YOLO : 이미지를 수십 개의 박스로 나누어 객체 탐지
- GAN : 생산적 적대 신경망
나이브 베이즈
베이즈 이론 정의 : 확률을 해석하는 이론 중 하나
베이지안 확률 정의 : 사전확률과 우도확률을 통해 사후확률을 추정
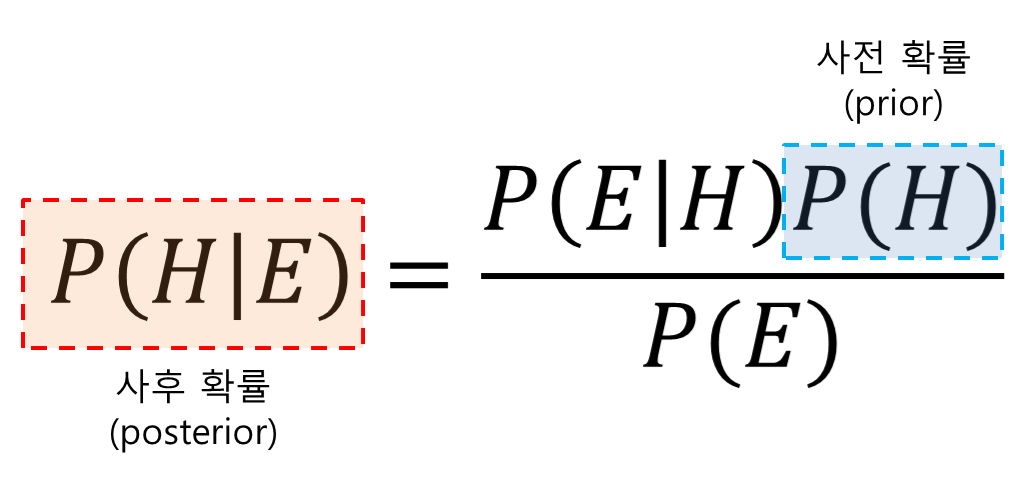 Untitled.png
Untitled.png
나이브 베이즈 정의 : 베이즈 정리를 기반으로 한 지도학습 모델
나이브 베이즈 활용 : 스팸메일 필터링, 텍스트 분류
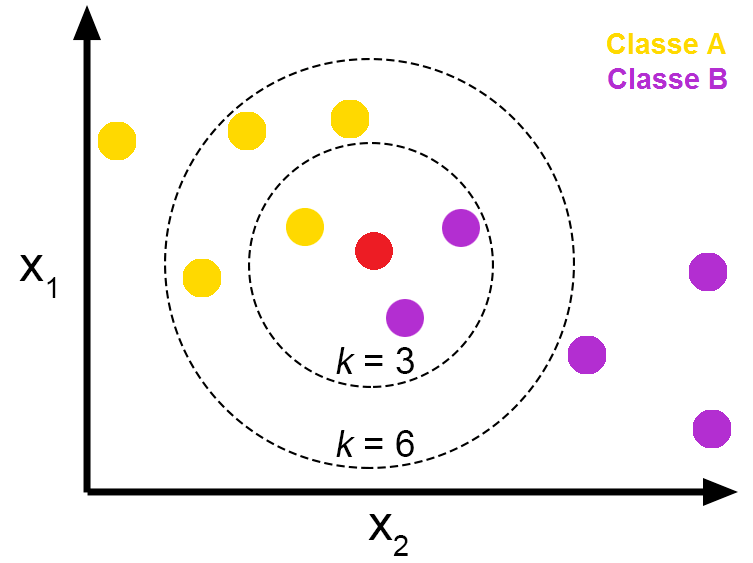
K-NN
 Untitled.png
Untitled.png
- 지도학습에 속하지만 군집의 특성도 있어 Semi(준)-지도학습으로 분류하기도 함
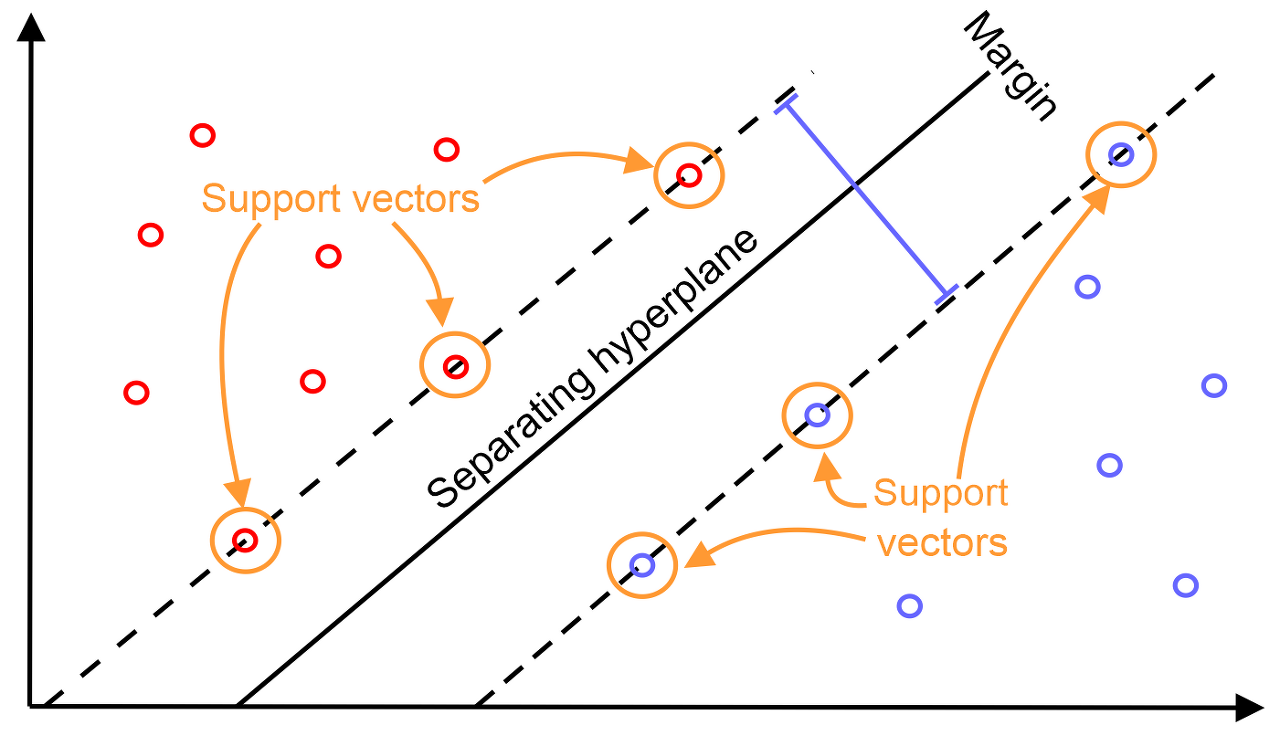
SVM
 Untitled.png
Untitled.png
- 분류 성능이 뛰어나 자주 사용
분류 모형 성과평가
평가 기준
- **일반화** : 다른 데이터에서도 안정적인지 여부
- **효율성** : 계산 양 대비 모형 성능 고려
- **분류 정확성** : 분류 결과 정확성
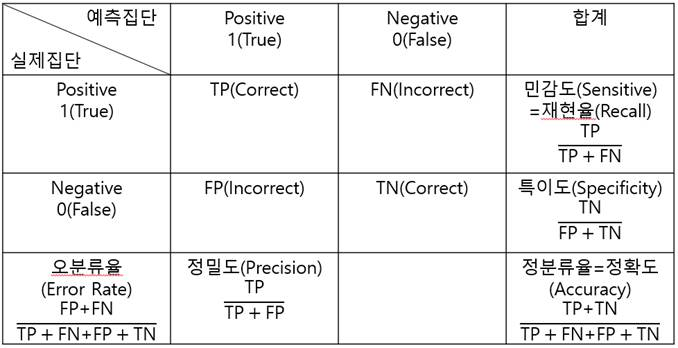
오분류표 (혼동행렬)
 Untitled.png
Untitled.png
- 정의 : 실제값과 예측칭의 값에 대한 옳고 그름을 표로 나타낸 것
- 구성
- 정확도(Accuracy) : 전체 관측치 중 올바르게 예측한 비율
- 오분류율(Error Rate) : 전체 관측치 중 잘못 예측한 비율
- 민감도=재현율(Sensitivity) : 실제 True 중 올바르게 찾아낸 비율
- 특이도(Specificity) : 실제 False 중 올바르게 찾아낸 비율
- 정밀도(Precision) : 예측 True 중 올바르게 찾아낸 비율
-
F1-Score : 정밀도와 재현율의 조화평균 값
\[\text{F1-score}=2 \times \frac{Precision \times Recall}{Precision + Recall}\] - FRR(False Positive Rate) : 실제 Negative 중 잘못 분류한 비율
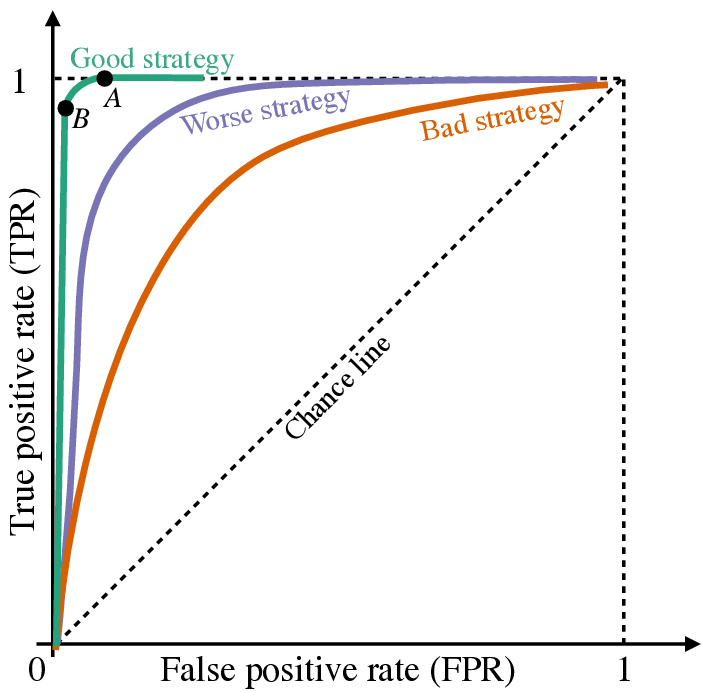
ROC curve
 Untitled.png
Untitled.png
- 정의 : 분류 분석 모형의 평가를 쉽게 비교할 수 있도록 시각화한 그래프
이익도표(Lift chart)
- 정의 : 모델의 성능을 판단하기 위해 작성한 표
향상도 곡선(Lift curve)
- 정의 : 랜덤 모델과 비교하여 해당 모델의 성과가 얼마나 향상되었는지 구간별로 파악하기 위한 그래프
3.9. 군집분석
군집분석 정의
데이터 간 유사성을 측정하고 몇 개의 군집(Cluster)로 묶고 각 국집에 대한 특징을 파악하는 기법
군집분석 거리측도
- 연속형 변수
- 유클리디안(Euclidean) : 두 점 사이의 가장 짧은 거리 계산
- 맨하튼(Manhattan) : 길을 따라 갔을 때의 거리
- 체비셰프(Chebychev) : 거리 차이 중 최댓값
- 표준화(Standardized) : 유클라디안 거리를 표준편차로 나눔
- 마할라노비스 : 표준화 거리에 변수 간 상관성까지 고려한 거리
- 민코프스키 : 유클리디안 거리와 맨하튼 거리를 한번에 표현
- 범주형 변수
- 단순 일치 계수 : 두 객체 간 상이성을 불일치 비율로 계산
- 자카드 거리 : 두 집합 사이의 유사도를 측정 (다르면 1, 같으면 0)
- 코사인 유사도 : 크기가 아닌 방향성을 측정하는 지표 (다르면 -1, 같으면 1)
- 순위 상관계수 : 순서척도인 데이터 사이의 거리를 측정하기 위한 지표 (스피어만 상관계수 이용)
계층적 군집분석
유형
- **병합적** : 가까운 데이터부터 순차적으로 병합하는 방법
- **분할적** : 각 데이터가 종료조건이 만족할 때까지 순차적으로 분할하는 방법
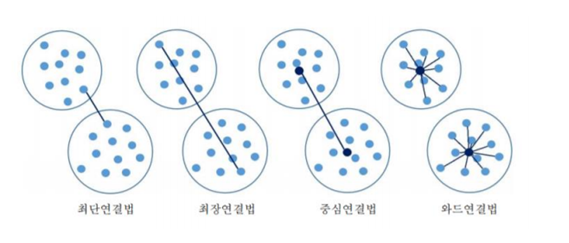
군집 간 거리측정
 Untitled.png
Untitled.png
- 단일연결 : 최단연결법, 군집 간 가장 가까운 데이터 거리 계산
- 완전연결 : 최장연결법, 군집 간 가장 먼 데이터 거리 계산
- 평균연결 : 군집 내 평균 데이터로 거리 계산
- 중심연결 : 군집의 중심점을 기준으로 거리를 계산
- 와드연결 : 생성된 군집과 기존의 데이터들의 거리를 군집 내 오차가 최소가 되는 데이터로 계산
비계층적 군집분석
정의 : 군집의 수를 사정에 정의해 정해진 군집의 수만큼 생성하는 방법
K-means
- 정의 : 군집 수(k)를 사전 정의한 뒤 집단 내 동질성과 집단 간 이질성이 높게 군집하는 알고리즘
- 특징
- 단순하고 빠름
- 초기값 K 설정 어려움
- 이상값에 민감함
- 단계 (반복)
- K개의 seed 설정
- 데이터 seed 할당
- 중앙값계산
- seed 재설정
- 군집 재할당
DBSCAN
- 정의 : 개체들이 밀집한 정도에 기초하여 군집을 형성하는 밀도 기반 군집분석 방법
혼합분포 군집
정의 : 확률분포에서 추출된 데이터끼리 군집화하는 분석 기법
EM 알고리즘
- 정의 : 확률모델의 최대가능도를 갖는 모수와 함께 가중치를 추정하는 알고리즘
- 단계 : E-step과 M-step 단계로 구성
- [E-step] 파라미터(모수) 설정
- [E-step] Z 기대값 계산
- [M-step] 새로운 파라미터 추정
- [M-step] 반복 및 종료
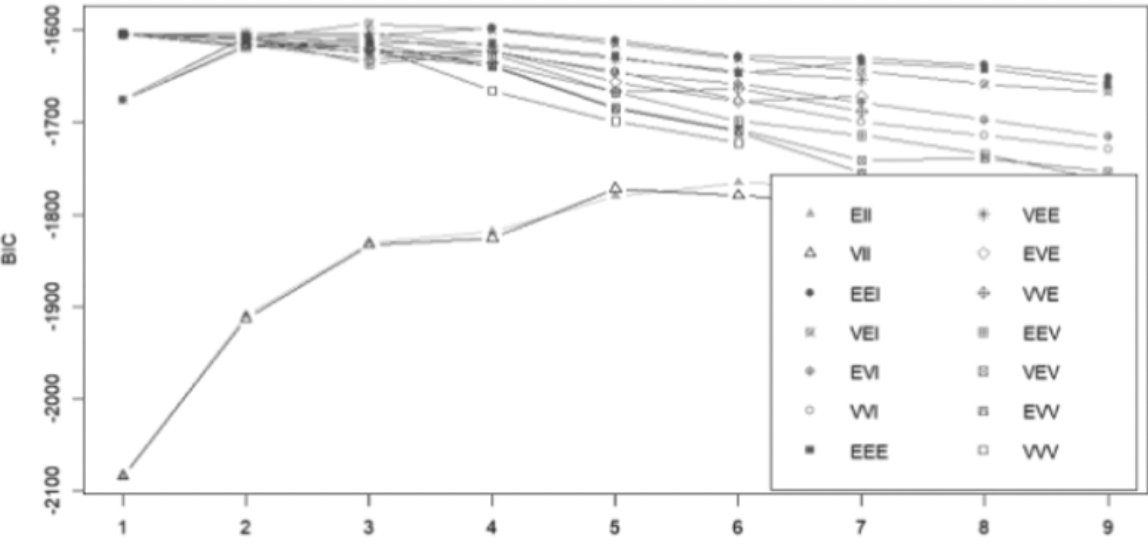
BIC 그래프
 Untitled.png
Untitled.png
- 모형 기반 군집분석 시 적절한 확률분포 수를 결정하기 위하여 사용.
- BIC값이 가장 큰 군집 수가 가장 적절하다. (위에선 3)
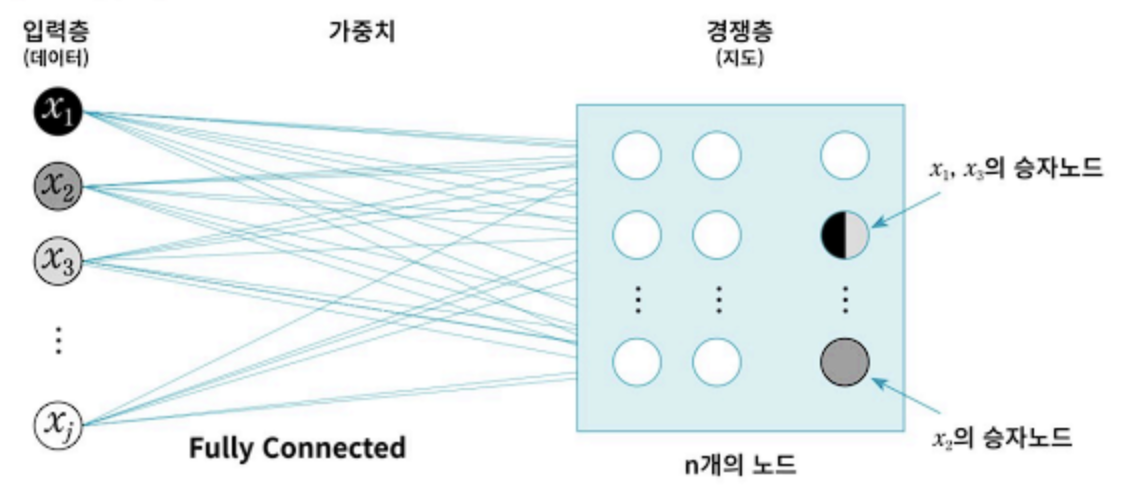
자기조직화지도(SOM)
 Untitled.png
Untitled.png
- 정의 : 인공신경망 기반 차원 축소와 군집화를 동시에 수행하는 알고리즘
- 구성:
- 입력층
- 경쟁층 : 표현하고자 하는 n개의 노드로 구성된 레이어
- BMU(Best-Matching Unit) : 입력층의 표본 벡터에 가장 가까운 프로토타입 벡터
- 승자노드(winning node) : BMU로부터 가장 가까운 경쟁층 노드
- 특징
- 순전파만 이용하여 빠름
- 시각적 이해용이
- 데이터 속성 보존
- 초기 설정 영향도 높음
- 경쟁층 노드 수 선정 어려움
군집분석 모형 평가
- 외부 평가
- 자카드 계수 평가
- 혼동행렬
- ROC curve
- 내부 평가
- 단순계산법
- 거리 측도 이용
- 실루엣 계수
- 엘보 메소드
3.10. 연관분석
연관분석 정의
데이터의 패턴을 분석하여 의미있는 규칙을 찾아내는 분석 기법
연관분석 특징
- 계산이 단순하며 분명함
- 목적변수가 없으므로 데이터 탐색 가능
- 품목 수가 많을 수록 계산량 증가
- 거래 발생이 없을 시 분석 불가
연관분석 측도
- 지지도 : 두 개의 품목이 동시에 포함된 거래의 비율
- 신뢰도 : 하나의 품목이 구매되었을 때 다른 품목 하나가 구매될 확률
- 향상도 : 품목 B가 구매될 확률 대비 품목 A가 구매될 때 품목 B가 구매될 확률
| 향상도 < 1 | 음의 상관관계 | A가 구매될 때 B의 구매확률 감소 |
|---|---|---|
| 향상도 = 1 | 관계 없음 | A와 B의 구매 관계 없음 |
| 향상도 > 1 | 양의 상관관계 | A가 구매될 때 B의 구매확률 증가 |
연관분석 알고리즘
Apriori
- 정의 : 지지도 사용하여 빈발 아이템 집합을 판별, 계산 복잡도를 감소시키는 알고리즘
- 절차
- 최소 지지도 설정
- 최소 지지도 보다 큰 지지도를 갖는 품목 선별
- 연관 규칙 탐색
- 반복
FP-Growth
- 정의 : 지지도가 낮은 품목부터 집합을 생성하는 상향식 알고리즘
- 특징
- Apriori 보다 빠르고 연산 비용이 저렴
« ADsP 2과목.
설비 예지보전 기술 »